If you're anything like me, life is an inconvenient struggling slow wade through treacle. The best invention since sliced bread is the ability to speed up podcasts, audiobooks, and YouTube videos to a point where they keep my attention rather than becoming background noise with an eternity between each word. And if you're not like me, well then, that just raises a lot of questions 🤪.
Which also means reading long blocks of text can be frustrating when I just want the answer, surely you've all experienced finding a recipe online, only to be bombarded with stories from their childhood, pet allergies, recent holiday destinations, and the entire history of basil. Basically what it must be like reading my Stephen-King-style blog posts that could easily be used to prop open a heavy door in a hurricane if printed 📖.
Why I created the 'listen to this post' audio
Since this is a new blog and I'm already looking for ways to enhance and customise it, and being very aware that people have their own preferences for consuming and learning information in different modalities. VARK - Visual (seeing it), Aural (hearing it), Reading (it), Kinesthetic (hands on touching it).
The words and screenshots will go some way to cover the Visual and Reading aspects, and I'm not sure I can help with whatever it is you have your hands on right now, but I can do something about Aural 😛 .
And also, needless to say... AI is cool right? And this doesn't have anything to do with AI other than Microsoft put it in the product name.
Getting Started
I briefly looked at the various open source options out there, but thought I'd give the almighty Microsoft a go. So I ended up trying out the Azure AI Speech services.
Very easy to setup and start playing, create a 'Speech Services' instance and it gives you a couple of keys and region string.
Quickest way to actually use it is via the Azure AI Speech CLI (it does work in PowerShell, but seems like it was designed for and works a bit better in 'Windows Terminal' instead).
If you're more adventurous there are samples, SDK, and articles for using C#, C++, Go, Java, JavaScript, Objective-C, Python, REST, and Swift. As well as the CLI and Azure Portal. There's even a fairly advanced Speech Studio where you can jump into the Audio Content Creation tool (I'll cover it a little bit later on in this article).
CLI Setup and Testing
You could always follow the Microsoft Azure AI Speech CLI quickstart guide, but if you'd rather rattle your way through this instead, I'm happy to have you along for this ride.
Installation is as simple as this one liner
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIAnd then configure the authentication using the key and region from the service you created.
spx config @key --set <SUBSCRIPTION-KEY>
spx config @region --set <REGION>And this is for PowerShell - you can see the addition of the --% parameter after the executable, that's to prevent PowerShell from incorrectly parsing the command line arguments.
spx --% config @key --set <SUBSCRIPTION-KEY>
spx --% config @region --set <REGION>Hello, Computer?
You can really have some fun with this bit, loads of voices and accents to choose from.
spx synthesize --text "Me Lob Yoy Long Tim" --voice "en-US-BrianNeural"
More Passion, More Energy, More Footwork
I'll be honest, the voices are a mixed bunch, some sound fairly decent, and some sound painfully obvious that they're synthetic.
There's various capabilities
- multi-style
- the same voice can be sad, cheerful, terrified, friendly, hopeful, whispering, or sound like a newscaster, or shout!
- multi-lingual
- the same voice is fluent in multiple languages and regional accent variations
- context aware
- to change the delivery based on the sentence structure and punctuation to change the pitch, rhythm, and intonation to better fit the written style used.
- NeuralHD
- highly expressive as well as context aware 'HD' voices.
I flicked through a bunch of voices, and the following seemed the best male voices, to represent my words on this site.
And this is the winner, meet "Davis" a NeuralHD voice - described as "Calm, Smooth, Soothing perfect for Audiobooks & Meditation".
Creative Potential
Probably not something I'll get deep into, but it's possible to add markup to manually adjust things like language, specific pauses, conversations back and forth between different voices in the same file, the specific style such as cheerfulness, empathy, calmness, and man more as well as the relative intensity of that style, even the role such as to sound like a different gender or age to play characters in stories etc.
This is done by using the Speech Synthesis Markup Language (SSML), it's an XML based format with the following structure. Too many options to go into here, take a look at this if you want to know more.
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="en-US">
<voice name="en-US-Andrew2:DragonHDLatestNeural">
<mstts:express-as style="cheerful">
Good morning Davis!
</mstts:express-as>
How are you today?
</voice>
<voice name="en-US-Davis:DragonHDLatestNeural">
Yeah, good thanks...
<mstts:express-as style="fearful" styledegree="2">
Erm, why do you ask?
</mstts:express-as>
</voice>
<voice name="en-US-Andrew2:DragonHDLatestNeural">
<mstts:express-as style="disgruntled" styledegree="1">
Ah no reason, nothing to worry your little head about.
</mstts:express-as>
<mstts:express-as style="disgruntled" styledegree="1.5">
You enjoy your day now...
</mstts:express-as>
<mstts:express-as style="shouting" styledegree="1.5">
<prosody volume="+30.00%">WELL?. do ya hear me?</prosody>
</mstts:express-as></voice>
<voice name="en-US-Davis:DragonHDLatestNeural">
<mstts:express-as style="terrified" styledegree="2">
Yeah.. ok.. will do Andrew, <mstts:express-as style="sad" styledegree="2">will do</mstts:express-as>.
</mstts:express-as>
</voice>
<voice name="en-US-Emma2:DragonHDLatestNeural">
<mstts:express-as style="empathetic" styledegree="2">
<break strength="medium" />
<prosody rate="-15.00%">
Don't worry about that crazy guy,
</prosody>
</mstts:express-as>
<mstts:express-as style="gentle" styledegree="2">
everything will be alright.
</mstts:express-as>
</voice>
</speak>I'd say that was pretty decent.
And that's only scratching the bare minimal surface of what the Azure AI Speech Services can do, other stuff includes speech recognition, translations, interactive conversations, intent recognition with conversational language understanding, create a virtual version of your own voice, and the ability to get facial positioning based on the phonemes in the spoken language to control movement of 2D and 3D models.
And it also creates Avatars! Wait, that doesn't look right with that word... where's the Papyrus font when you need it...
Azure AI Speech Studio Portal
Instead of using the API or the CLI, you can quickly hop into https://speech.microsoft.com/ with a range of features to explore across various scenarios, or specifically to do with Speech to Text, Text to Speech, or Voice Assistants.
Audio Content Creation
Under 'Text to speech' heading is the Audio Content Creation tool.
And this is where you can type out or copy/paste the script, and poke all the settings until it sounds just right, things like custom pronunciations with phonemes, or aliases to substitute words with an alternative, intonation, rate, pitch, volume, and breaks/silence.
It doesn't seem like you can pick the 'style' like we did directly with the SSML above, but you can still edit the SSML by toggling the handy button at the top right of the text area.
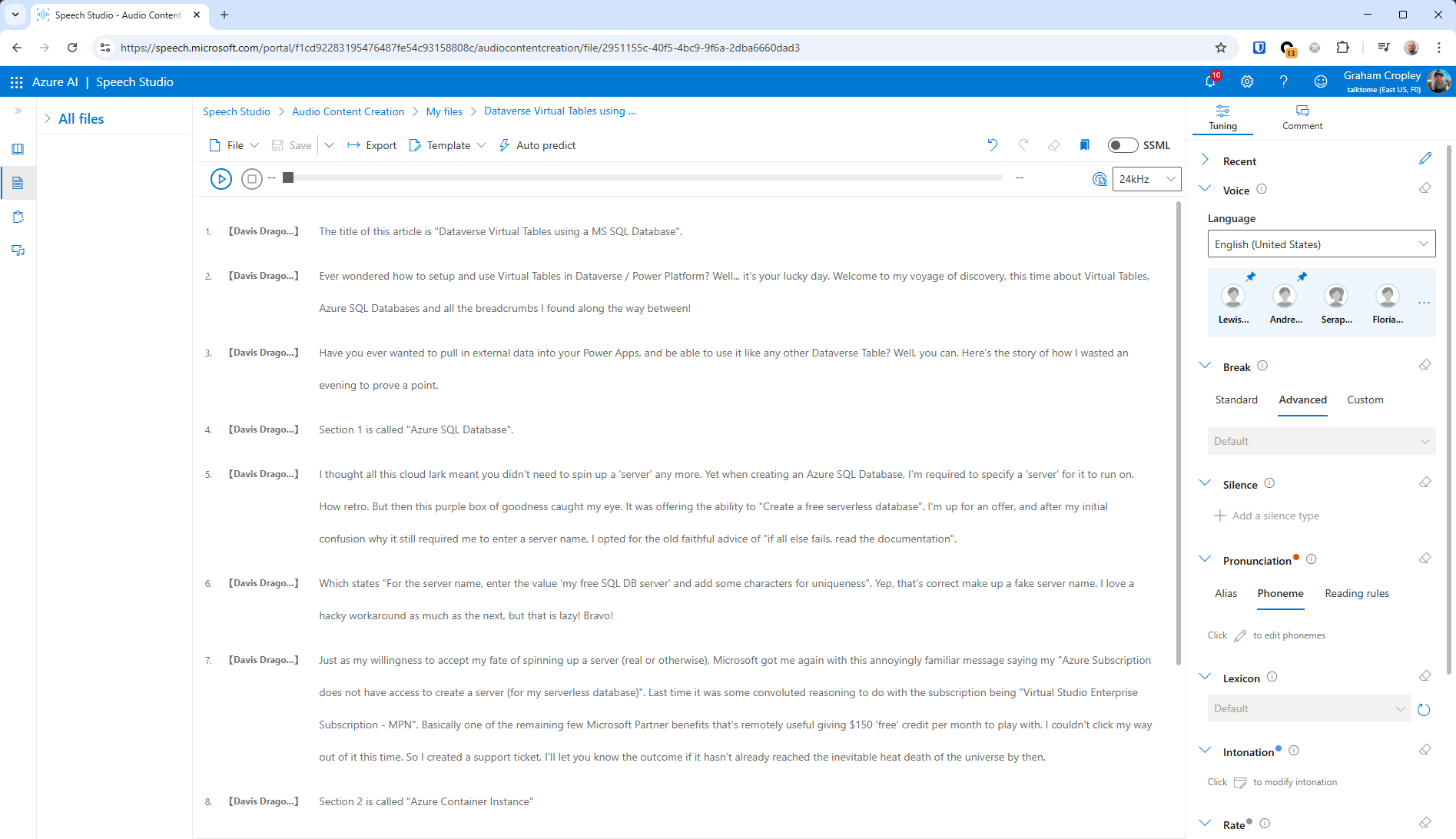
And there you go, the final product neatly displayed in a handy media player at the top of the page.